Automated Extraction of Insights from Educational Videos
Introduction
As the world adapted to the challenges of the COVID-19 pandemic, educational institutions embraced online learning through platforms like Google Meet and Zoom. To assist students in their studies, many online lectures were recorded by university professors for future reference during exam preparation. In the post-pandemic era, the reliance on these recorded lectures persists. Additionally, engagement with educational content on platforms like YouTube or Coursera has become increasingly prevalent, reflecting the integral role that online learning plays in our lives today. However, many challenges arise for students and learners: the often extended duration of these videos. This issue is further compounded for individuals with restricted access to a reliable internet connection. Frequently, learners encounter specific queries about a particular topic and seek precise answers. Additionally, the need for quick summaries of entire chapters or concise keywords to grasp fundamental concepts becomes apparent. These challenges underscore the evolving landscape of online education, emphasizing the importance of addressing accessibility and facilitating efficient learning. In recent years, Artificial Intelligence has emerged as a valuable solution to tackle such challenges. With the integration of AI and automation, we can derive insights and extract pertinent information from recorded lectures and educational videos available on the internet. By leveraging recent advancements in text summarization, transcription, keyword extraction, sentiment analysis, and other natural language processing tasks, our aim has been to create a tool for online learners. This tool is designed to support individuals in their learning journey by providing assistance in navigating educational content. All of this was part of an academic project within the context of the Natural Language Processing course at ESPRIT School of Engineering in 2023.
Project Overview
The purpose of this academic project is to create a web application that is able to:
- Transcribe the spoken content of the lecture, converting speech into a readable text format.
- Identify and extract keywords from the lecture.
- Analyze the tone and sentiment expressed in different parts of the lecture.
- Provide relevant answers to users’ questions based on the lecture content.
Users initiate the process by uploading a video file or entering a YouTube URL containing the desired lecture. The key features of this application are transcription, keyword extraction, sentiment analysis and question answering. To technically achieve that, we will train or fine-tune natural language processing models for those different tasks. Most of the models will be fine-tuned on French data since the lectures are in French. The application will be deployed on a web server and will be accessible through a web browser.
Technical Overview
⚫️ Transcription
Transcription is the process of converting speech into a readable text format. This is the first step in our application. We will be using Fast-Whisper, a reimplementation of OpenAI’s Whisper model using CTranslate2, which is a fast inference engine for Transformer models. This implementation is up to 4 times faster than openai/whisper for the same accuracy while using less memory. Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification. Here’s an overview of its architecture:
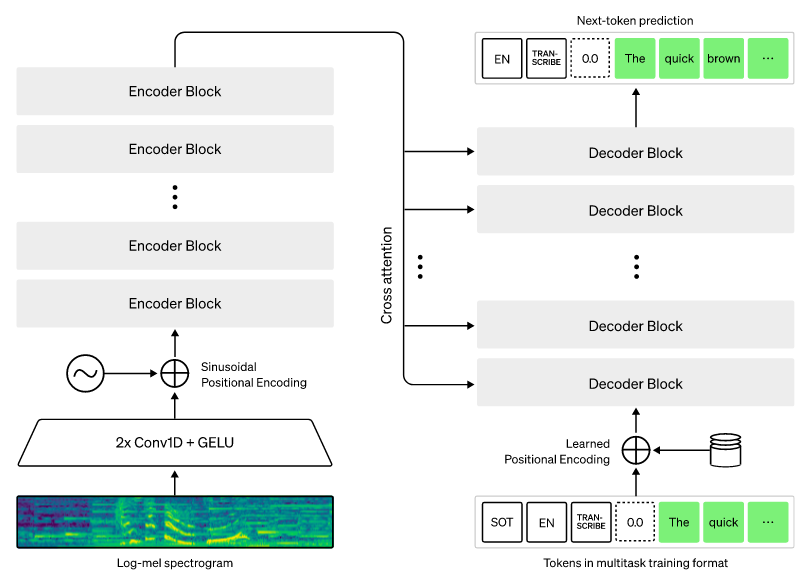
Read more about Faster-Whisper here and Whisper here.
After converting the video file to audio, we feed it to the Faster-Whisper model to get the transcribed text. Later, multiple preprocessing steps will be applied to the text depending on the task.
⚫️ Summarization
Text summarization is the task of creating a short, accurate, and fluent summary of a longer text document. It is one of the most challenging and interesting problems in the field of natural language processing (NLP). It is also one of the most important and difficult tasks that require a deeper understanding of the language. In this project, we will be using Pegasus, a state-of-the-art model for abstractive text summarization.
📊 Dataset
For this task, we will be using the CNN/Daily Mail dataset. It is an English-language dataset containing just over 300k unique news articles as written by journalists at CNN and the Daily Mail. The current version supports both extractive and abstractive summarization, though the original version was created for machine reading and comprehension and abstractive question answering. You can find more details about the dataset on HuggingFace here.
🤖 Model
As mentioned, we will use Pegasus, which was proposed in the research paper “PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization” in 2019. It is a state-of-the-art model for abstractive text summarization. It is based on the Transformer encoder-decoder architecture and is pretrained using a combination of the masked language modeling (MLM) and the gap sentence generation (GSG) objectives. The model is trained on a large corpus of English text (750GB) and has 568M parameters. Its output is a sequence of tokens selected by the model using beam search decoding algorithm. The selected sequence of tokens forms the final output summary with a fixed maximum length of 128 tokens. Here’s an overview of the Pegasus architecture:
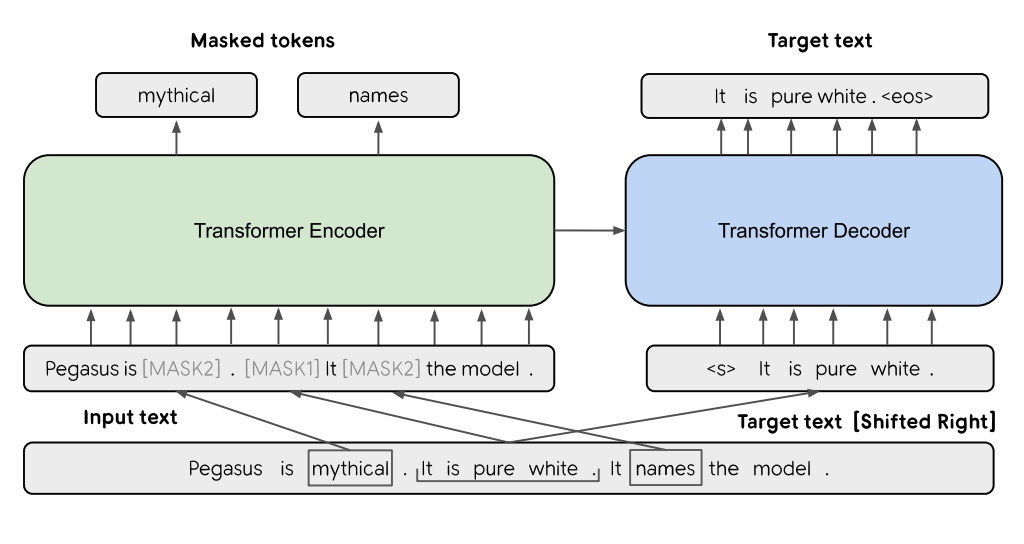
🎯 Approach
We will fine-tune Pegasus on the CNN/Daily Mail dataset for the abstractive summarization task. The fine-tuning process will be done using Transformers library from HuggingFace. After that, the model will be evaluated using the ROUGE metric. ROUGE is a set of metrics for evaluating automatic summarization of texts as well as machine translation. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
⚫️ Keyword Extraction
Keyword extraction is the task of automatically extracting the most relevant words and phrases from a document. These keywords can be used to summarize and understand the content of the lecture. In this project, the extracted keywords can be used to summarize the lecture and provide a quick overview of the content. Additionally, the keywords can be used to search for specific topics in the video. Our investigation into optimizing the process of keyword extraction has led us to uncover several approaches. We have identified the following methods: KeyBERT, YAKE, RAKE, and fine-tuning CamemBERT with a custom dataset. These methodologies shows potential in extracting keywords from various types of textual data.
- KeyBERT stands out as a powerful technique that utilizes BERT-based embeddings to generate representative keywords. By leveraging the contextual information captured by BERT, KeyBERT offers a comprehensive and nuanced approach to keyword extraction.
- YAKE (Yet Another Keyword Extractor) presents a noteworthy alternative, employing an unsupervised approach based on statistical measures such as term frequency and inverse document frequency (TF-IDF) to identify salient keywords.
- RAKE (Rapid Automatic Keyword Extraction) is another notable method that relies on statistical heuristics, such as word frequency and co-occurrence, to extract keywords from text. This unsupervised technique is particularly adept at handling longer documents and can produce informative and concise keyword sets.
- Fine-tuning CamemBERT, a variant of BERT designed specifically for French language processing, on a custom dataset shows promise for keyword extraction tasks in French text. By adapting the pre-trained model to domain-specific or task-specific data, we can enhance its ability to accurately extract relevant keywords from French transcripts.
In this project, we will be focusing on the last approach which is fine-tuning CamemBERT on a custom dataset for keyword extraction.
📊 Dataset
We created a dataset by merging data from transcribed YouTube videos with the WikiNews French keywords dataset. This dataset contains approximately 340 documents and consists of two columns: “text” and “keywords.” To collect the dataset, we created a tool to scrape and transcribe youtube videos using Faster-Whisper, PyTube, and yt-dlp.
🤖 Model
We used CamemBERT, a state-of-the-art language model for French, to perform keyword extraction. CamemBERT is a pre-trained language model based on Facebook’s RoBERTa model released in 2019. It was trained on 138GB of French text, which is 2.5 times the size of the French Wikipedia. CamemBERT is a powerful language model that can be used for a variety of downstream tasks, including text classification, question answering, and summarization. Transformer-based models are the current state-of-the-art for NLP tasks. It’s a neural network architecture that uses attention mechanisms to learn contextual relations between words in a text, and it was introduced in 2017 in the paper Attention Is All You Need. CamemBERT-base model is composed of an embedding layer to represent each word as a vector, followed by 12 hidden layers composed mainly of two types of transformations: self-attention transformations and dense transformations. The model has 12 hidden layers, 768 hidden size, 12 attention heads, and 110 million parameters. Here’s an overview of the CamemBERT architecture:
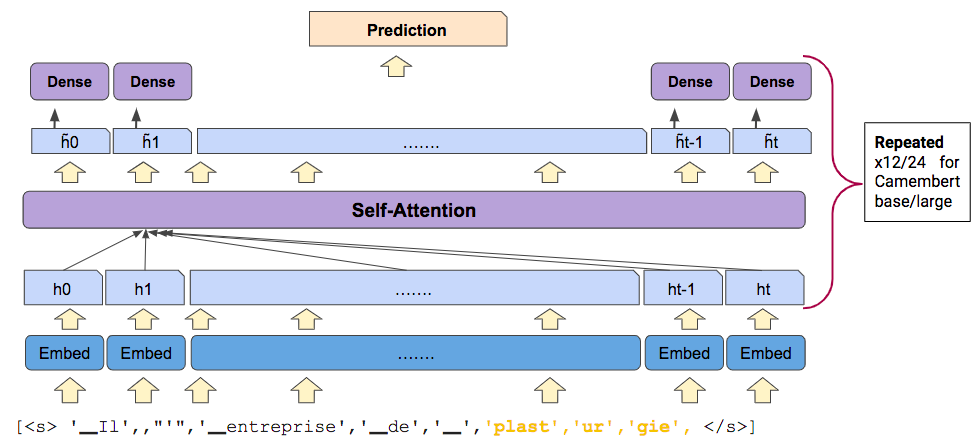
You can find more details on the CamemBERT’s official website here.
🎯 Approaches
Approach 1: Pre-finetuning on Sentence Similarity, followed by Fine-tuning for Keyword Extraction
In this approach, we first pre-finetune CamemBERT on the task of sentence similarity. By training the model to understand the semantic relationships between sentences, it gains a deeper understanding of contextual information. Subsequently, we fine-tune the pre-finetuned model specifically for keyword extraction. This two-step process allows CamemBERT to leverage its enhanced comprehension of language semantics to accurately identify and extract keywords.
Approach 2: Direct Fine-tuning for Keyword Extraction
In this streamlined approach, we directly fine-tune CamemBERT for the keyword extraction task without pre-finetuning on sentence similarity. By focusing solely on the target task, we optimize the fine-tuning process and enable CamemBERT to learn directly from the keyword extraction data, and just benefit from its language representation capabilities.
In both approaches, we fine-tune CamemBERT on our custom dataset and evaluate the model performance using the F1-score metric. We also produce quantized versions of the fine-tuned models to reduce their size and facilitate deployment.
⚫️ Sentiment Analysis
Next up, we have the sentiment analysis part which is used to predict the tone and motive of the speaker in the video, this will help provide more context to the situation as well as understanding the scenario. As usual, using the transcribed text as input, this time into the BERT-ABS for abstractive sentiment analysis with over a 140M parameters. The output of BERT-ABS can be represented as a set of (aspect_term, polarity_label) pairs, where aspect_term is a string representing the aspect term and polarity_label is a string representing the predicted sentiment polarity label for that aspect. The polarity label can take one of three values: positive, negative, or neutral. For the fine-tuning part, we will be using MAMS (Multimodal Aspect-based Sentiment Analysis) dataset, which provides aspect-based sentiment annotations for YouTube video comments in order to perform fine-tuning of BERT-ABS and we will evaluate the final results using F1-score.
⚫️ Question Answering
For this task, we will be dealing with the question answering functionality, more precisely reading comprehension of the transcribed text. We input the text and pose a question to the model and see if it gets the answer correctly. The model is based on BERT architecture but specifically trained on a large corpus of French text (138 Gb of French text) -> 110 million parameters. The output is the answer to the question asked. For the fine-tuning part, we used the camemBERT model which was fine-tuned on the FSQuAD (French Squad) dataset and fine-tuned it on the downstream task of open question answering.
Deployment
To build our application, we used React for the frontend and FastAPI for the backend. The frontend is responsible for the user interface and the backend is responsible for the business logic and the communication with the different models using REST APIs. Fine-tuned models were exported and integrated all together in the backend. When a user uploads a video or provide a video URL, the frontend sends a request to the backend to start the transcription process. Once the transcription is done, the backend starts the summarization, keyword extraction, sentiment analysis, and question answering processes. Once all the processes are done, the results are displayed to the user.
Here’s an overview of the application: